AI as first reviewer: why the human still decides
AI can make idea evaluation faster by scoring submissions, surfacing risks, detecting overlap, and drafting review notes, but it should never become the final decision-maker. In Sparqbox, AI acts only as a first reviewer: humans own the final score, status change, routing, and feedback to the submitter, with every decision remaining auditable and accountable. This human-in-the-loop architecture protects trust, reduces governance risk, and ensures AI improves the process without replacing human judgment.
By Dennis Jacobs
AI as first reviewer: why the human still decides
AI can score an idea against the criteria you have defined, surface risks, flag overlap with existing work, and rank submissions by weighted score. It cannot decide which idea is right for your company. The distinction between recommender and decision-maker is the most important architectural choice in any idea management tool that uses AI, and most tools in the category are getting it wrong by collapsing the two. This article walks through why the line matters, what AI is genuinely good at in idea evaluation, and how Sparqbox enforces the boundary in the underlying software.
The two camps in "AI for innovation" right now
The category currently splits into two design philosophies. The first treats AI as the central decision-maker. Submit an idea, the AI evaluates it, ranks it, and produces a recommendation that approximates a verdict. Some tools go further: the AI auto-approves, auto-rejects, or auto-routes ideas based on its own confidence scores. The human appears only to review the AI's choices, which most do not, because reviewing every recommendation defeats the purpose of automating the work.
The second treats AI as a recommender that feeds into a human-owned process. The AI scores, surfaces, flags, and drafts. The human reviews, weights, and decides. The outputs of the AI are inputs to a deterministic process that the AI itself does not control. If the AI is unavailable or wrong, the workflow continues without it.
Sparqbox is in the second camp by deliberate architectural choice. The decision is not about AI being insufficient. The current generation of language models is genuinely good at scoring text against criteria, which is what an idea evaluation tool needs. The decision is about what a tool that affects employees inside a company is allowed to do without human accountability behind it.
Why letting AI decide is the wrong design
Four problems make AI-as-decision-maker unworkable in idea evaluation, and they get worse the more important the decision becomes.
The first is calibration. AI scores ideas against the patterns in its training data and the prompt it has been given. Both can drift. The training data ages out of relevance as the world changes. The prompt may not capture the current strategic priorities of the company. An AI that scored an idea as a 4.2 in March may score the same idea as a 3.7 in September, not because the idea changed, but because the model was updated. Decisions made on drifting scores cannot be audited, because there is no stable ground truth.
The second is context. AI does not know what your company is actually doing this quarter, which projects already exist that overlap with the idea, what the founder said in last month's all-hands about strategic direction, or that the engineering team is overbooked until Q4. Humans on the inside know all of this. AI can be told some of it through prompt engineering, but the gap between what is in the prompt and what is in someone's head is exactly the gap where bad recommendations come from.
The third is accountability. When the AI rejects an idea and the employee asks why, the answer cannot be "the AI thought so." Someone has to own the decision, defend the reasoning, and accept the consequences. AI cannot be held accountable in any meaningful sense. Pretending otherwise pushes accountability onto the people who deployed the AI without acknowledging that they did. This is exactly the situation EU regulators have been writing rules against: the AI Act's high-risk provisions for workplace AI take effect on 2 August 2026, and require meaningful human oversight for decisions affecting employees. "The AI told me" is not oversight.
The fourth is conservatism. AI is trained to predict what is similar to what already exists. The ideas worth pursuing are often the ones that do not fit the existing patterns. A model optimized to recognize good ideas based on past data will systematically underrate the unfamiliar and overrate the conventional. This is the opposite of what an idea evaluation process should be doing.
These four failures do not mean AI is useless in idea evaluation. They mean AI should not be the one making the call.
What AI is genuinely useful for as a first reviewer
If AI is not the decision-maker, what is its actual role? Sparqbox uses the name "AI first reviewer" deliberately. AI does what a thoughtful first reviewer does inside a well-run idea program: a careful pass that surfaces useful information for the humans who will decide.
Five jobs the AI first reviewer does well in Sparqbox:
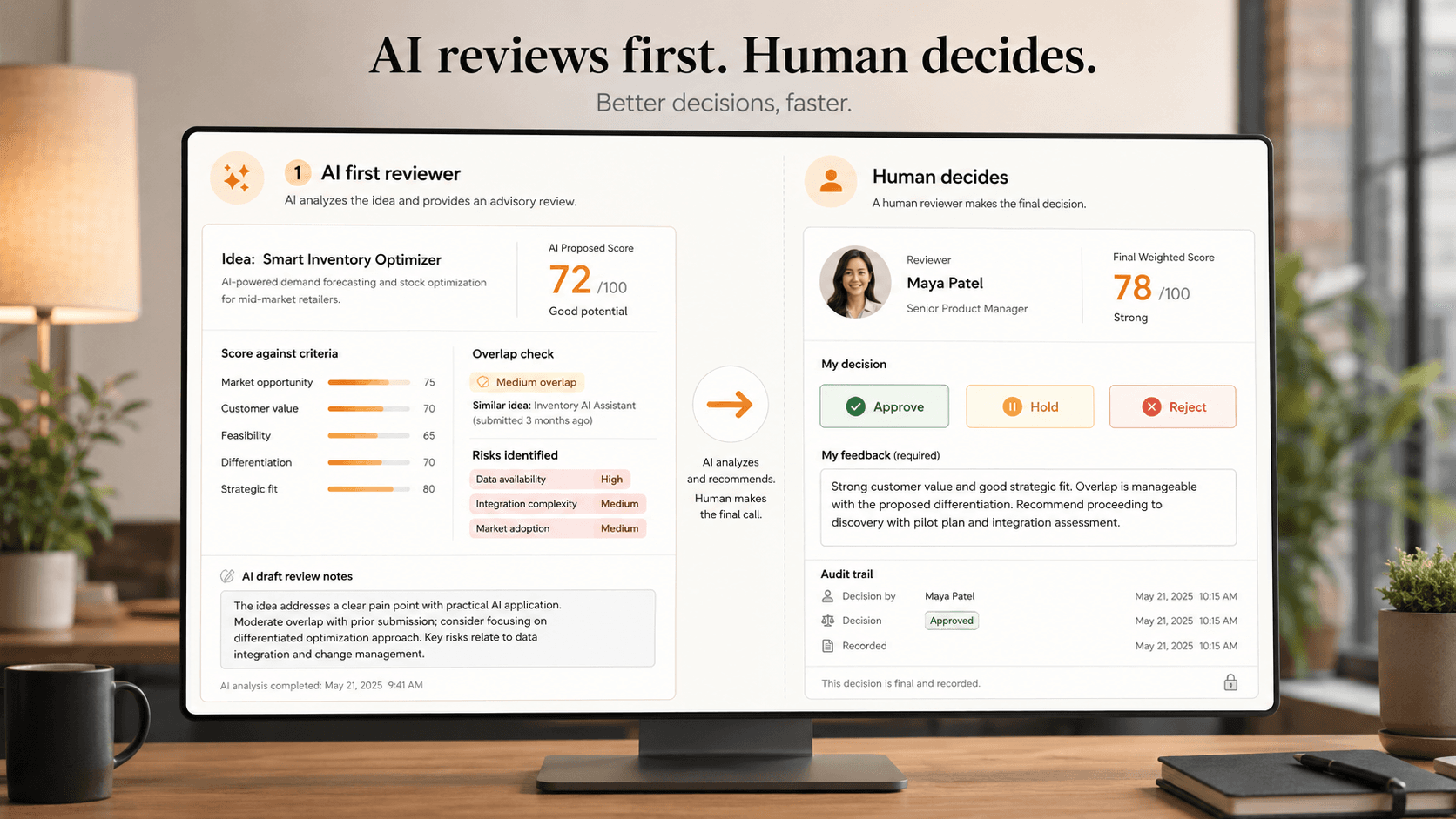
It scores each idea against the configured weighted criteria on a Likert scale, the same scale the human reviewers use. The score is non-binding. It functions as a baseline that humans can agree with, disagree with, or override entirely. When several humans score independently and the AI's score sits within their range, that is a signal of convergence. When the AI score is an outlier, that is a signal worth examining.
It detects overlap with existing ideas. The product runs PostgreSQL trigram similarity matching on titles and descriptions, returning probable matches before the submitter even finishes typing. The AI layer enhances this with semantic similarity, catching cases where two ideas describe the same thing in different words. The recommendation goes to the submitter as "this idea looks similar to these existing ones, do you want to support one instead." The decision to merge or proceed remains the submitter's.
It surfaces risks against the company's stated context. Tenants configure AI org-context fields: industry, size, what kinds of ideas are off-strategy this year, regulatory sensitivities. The AI uses this to flag ideas that may conflict with stated context, without rejecting them. A human still decides whether the flag is genuine.
It drafts evaluation notes for human reviewers to refine. Reviewing an idea cold takes effort. Reviewing an idea with a draft analysis to react to is faster and produces better human evaluation, because the human spends their attention on agreement and disagreement rather than on cold synthesis.
It runs in the background continuously, picking up newly submitted ideas without anyone having to remember to assign them. Speed of first response is one of the most predictive variables for whether an idea program retains its submitters. AI as first reviewer guarantees a same-day baseline evaluation that the human review can build on, without burning out any single reviewer.
These are the jobs of a recommender. None of them is the job of a decision-maker.
What AI must never own
The list of things AI does not own in Sparqbox is explicit, both in the product principles and in the underlying architecture.
AI does not calculate the final weighted score. The weighted score in Sparqbox is a deterministic calculation: the sum of each criterion score multiplied by its weight, where the weights sum to 1.000 with a tolerance of plus or minus 0.001. The math lives in a service module the AI never touches. The AI contributes one score among several, and its contribution is configurable per tenant (Sparqbox admins set how much the AI score counts toward the minimum reviewer count, and how heavily it is weighted relative to humans). The final number is computable by hand.
AI does not transition status. When an idea moves from "in review" to "approved" or "rejected," that transition is triggered by a human action, recorded with a named user in an append-only status log. No AI-initiated status change is possible, by design.
AI does not write the feedback to the submitter. The mandatory feedback loop is owned by a human. The product enforces that no idea can be closed in an "approved" or "rejected" state without explicit feedback text written by a human reviewer. AI can draft the feedback to save time, but a human must read, edit, and submit it.
AI does not assign coordinators or reviewers. Routing happens by rules a human configured. AI can suggest a coordinator based on category match, but the configuration is human-set, and the assignment is human-approved.
AI does not gate workflow. If the AI service is degraded or unavailable, the human workflow continues with no interruption. Ideas can still be submitted, scored manually, decided, and closed. The AI first reviewer is additive to the process, never load-bearing.
The boundary is enforced in code, not by policy. Service modules have specific responsibilities. The scoring_service owns the deterministic math. The AI service is a feature that other services call optionally. A human path exists for every workflow that the AI accelerates.
The governance argument
Software buyers in 2026 are paying attention to AI governance in ways they were not in 2024. Three things are driving the shift.
The EU AI Act, in force since August 2024, classifies AI systems used for decisions about workers as high-risk under its Annex III. The high-risk provisions take effect on 2 August 2026, with requirements for transparency, human oversight, technical documentation, logging, and the ability to challenge outcomes. (A Digital Omnibus amendment with political agreement in May 2026 may extend the deadline to December 2027, but the original timeline is the prudent assumption until the amendment is formally adopted.) An idea management tool that lets AI auto-reject employee submissions is exactly the kind of system the Act was written to constrain. Compliance is not optional once the rules apply, and "the AI did it" is not a defense.
Procurement teams are asking new questions. Security reviews increasingly include a section on AI usage: what does the AI decide on its own, what does the human review, what is the audit trail, what happens if the AI is wrong. Vendors who collapse the recommender and decision-maker into a single AI step have a harder answer to those questions, and the harder answer often kills the deal.
Employees are noticing. A program that visibly uses AI to reject ideas without human review will lose submitter trust faster than a program that has no AI at all. The advantage of AI-as-first-reviewer is exactly that it does not have to hide behind opacity. The AI score is one input, visible to the submitter, alongside human scores, with clear authorship on the final decision. That transparency is a feature, not a constraint.
Where this lands in the product
The Sparqbox AI first reviewer runs as a non-blocking step in the idea evaluation pipeline. When an idea is submitted, it enters the queue. The AI evaluates it against the bucket's weighted criteria within minutes. The output is a draft score per criterion, a draft overall weighted score, a flag for overlap with existing ideas, and a flag for risk against the tenant's configured context.
The human reviewers (independent of the AI) see the AI's output as one column in the scoring interface, alongside their own. They score independently. The deterministic scoring engine combines the scores according to the configured weights and reviewer-count rules. The Innovation Manager (or whoever owns the workflow) sees the result and makes the call.
If the AI fails, nothing breaks. The score column from the AI is empty. The human scores combine into a valid weighted score. The decision proceeds.
This is what AI in idea management should look like in 2026 and beyond. Not less AI. Carefully bounded AI. The line between recommender and decision-maker is where the architecture lives or dies, and Sparqbox is on the right side of it on purpose. The underlying scoring framework comes from the 50-company benchmark Dennis ran for his TU Eindhoven thesis, and the product implementation is documented at how the evaluation process works.
Common questions
Can AI evaluate ideas as well as a human?
For straightforward scoring against well-defined criteria, current AI can produce evaluations that fall within the range a thoughtful human reviewer would produce. For decisions that require company-specific context, accountability, or recognition of unfamiliar but valuable proposals, AI underperforms humans systematically. The right design uses AI for the first kind of work and reserves humans for the second.
Why doesn't Sparqbox let the AI auto-approve obvious ideas?
Because what looks like an obvious approval to AI may have context the AI cannot see. The cost of letting the AI auto-approve is that some ideas will be approved without a human ever reading them, which defeats the audit trail and breaks the mandatory feedback loop. The cost of requiring a human to confirm even obvious approvals is small. The tradeoff is not close.
Does AI ever make the final scoring decision in Sparqbox?
No. The final weighted score is a deterministic calculation that combines the human and AI scores according to configured weights. The AI contributes one score (configurable per tenant, including the option to disable it entirely). The math is run by a service module that does not call the AI. The final number is auditable, reproducible, and unchanged if the same scores are entered again.
What happens if the AI score and human scores disagree?
The system surfaces the disagreement visibly. A large gap between the AI score and the average human score is itself useful information: either the humans are seeing something the AI missed, or the AI is calibrated differently than the humans on this category. Both cases are worth investigating before the decision is made. The disagreement does not block the workflow.
Is this compliant with the EU AI Act?
Yes. The AI Act requires meaningful human oversight for decisions affecting workers. Sparqbox's architecture keeps every decision in human hands by design, with the AI contributing inputs and recommendations that are visible, optional, and overridable. The audit log records which human made each decision and what scores informed it. Compliance is not a feature retrofit. It is the design.
The takeaway
The AI in an idea management tool should make humans faster, not replace them. It should surface, score, draft, and flag. It should not approve, reject, route, or write the final feedback. The line between the two roles is the design decision that determines whether the product is trustworthy under regulatory scrutiny, internal governance, and the basic test of whether employees still want to submit ideas after a year.
Sparqbox is built on the right side of that line. The architecture enforces it. The product principles state it. And the underlying scoring math runs without the AI when it has to.
